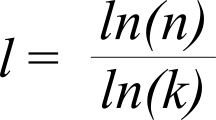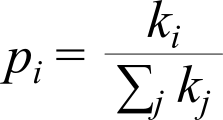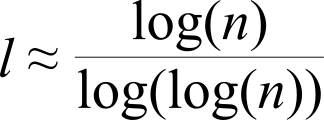Hypertext[1] is digital text containing hyperlinks. Hyperlinks[2] are pieces of selectable digital text (usually a single word, but it can also be a full sentence or a single letter) through which the user can gain direct access to other digital text (usually another document, but it can also be a location within the same document). The other digital text can itself be hypertext. A set of hypertext pages interconnected by hyperlinks is called a web, the most famous one is the World Wide Web[3].
Course
History
The origin of hypertext is generally traced down[4] to an article As we may think by Vannevar Bush published in July 1945[5]. In this article Dr. Bush encourages the development of a new way to access information.
The dream: To provide a record of ideas and to enable man to manipulate and to make extracts from that record so that knowledge evolves and endures throughout the life of a race rather than that of an individual.
The needs: A record if it is to be useful to science, must be continuously extended, it must be stored, and above all it must be consulted.
Text stored in electronic format has a couple of advantages over text stored in paper format. Firstly, the existing text is allowed to move. This means you can make additions anywhere in the document. You can choose to free up space to either add some words to a sentence or an entire section to a chapter. Secondly, the existing text is not permanent. It can be erased and replaced by something else, meaning you can make corrections at any time. Moreover, if the document is made available on the World Wide Web, these new insights are available to the public with the click of a button (instead of having to print new editions of already published papers). So at first glance, it seems that the nature of digital text already allows us to make a record that can be continuously extended and stored. The consultation part is what mainly concerned Dr. Bush and in particular the overwhelming amount of new published ideas such that:
... truly significant attainments become lost in the mass of the inconsequential. The summation of human experience is being expanded at a prodigious rate, and the means we use for threading through the consequent maze to the momentarily important item is the same as was used in the days of square-rigged ships.
Restrict the amount of additions? "No", said Dr. Bush: "Improve the way we can access information".
... For there may be millions of fine thoughts, and the account of the experience on which they are based, all encased within stone walls of acceptable architectural form; but if the scholar can get at only one a week by diligent search, his syntheses are not likely to keep up with the current scene.
Dr. Bush realized that whether or not a database is consulted boils down to the ease with which one can select the information desired.
The real heart of the matter of selection, however, goes deeper than a lag in the adoption of mechanisms by libraries, or a lack of development of devices for their use. Our ineptitude in getting at the record is largely caused by the artificiality of systems of indexing. When data of any sort are placed in storage, they are filed alphabetically or numerically, and information is found (when it is) by tracing it down from subclass to subclass. It can be in only one place, unless duplicates are used; one has to have rules as to which path will locate it, and the rules are cumbersome. Having found one item, moreover, one has to emerge from the system and re-enter on a new path.
The human mind does not work that way. It operates by association. With one item in its grasp, it snaps instantly to the next that is suggested by the association of thoughts, in accordance with some intricate web of trails carried by the cells of the brain.
Most people would agree with this statement. A smell or a piece of music can be enough to be instantly reminded of a certain occasion in your life. Dr. Bush therefore coined the term: Associative indexing.
... the basic idea of which is a provision whereby any item may be caused at will to select immediately and automatically another.
In other words: A hyperlink.
Concept
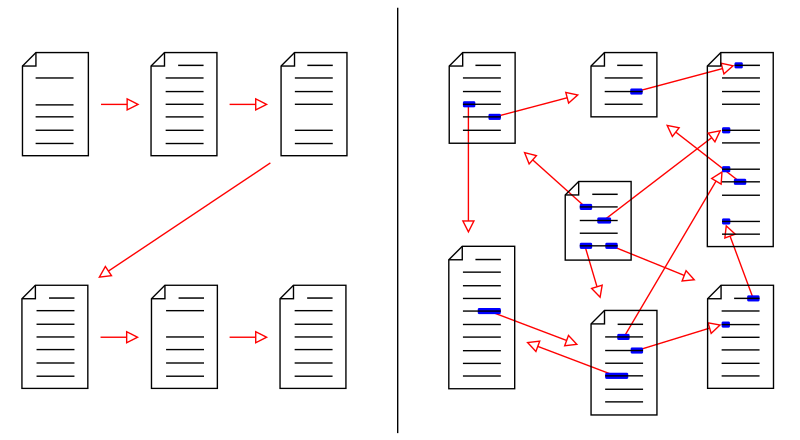
Hypertext deals with access to related information. When I read a book from a certain author and I like it, then I'm bound to be interested in any sequels, other books from the same author, reviews, what did other people that liked it also read, and so on. In the digital world, all this information is available on the World Wide Web and to allow quick access the concept of hypertext was introduced: Digital text that contains pieces of text through which the user can gain direct access to other digital text. The figure below shows the general idea in comparison to traditional text.
Traditional paper text is mostly sequential: What do you read after the first page? Well, the next page. Whereas the sequence in which you traverse (fragments of) websites is entirely up to you. The picture above can be interpreted as single pages in a book, but can equally well represent different books in (different) libraries. Hypertext not only allows you to follow your own thoughts and choose yourself what you want to read next. The next content is also just one click away.
Implementation
The implementation of a global hypertext system was formerly proposed in 1989 by an employee of CERN named Tim Berners-Lee. The section below is a quote from his original proposal[7]:
The principles of hypertext, and their applicability to the CERN environment, are discussed more fully in [1], a glossary of technical terms is given in [2]. Here we give a short presentation of hypertext.
A program which provides access to the hypertext world we call a browser. When starting a hypertext browser on your workstation, you will first be presented with a hypertext page which is personal to you: your personal notes, if you like. A hypertext page has pieces of text which refer to other texts. Such references are highlighted and can be selected with a mouse (on dumb terminals, they would appear in a numbered list and selection would be done by entering a number). When you select a reference, the browser presents you with the text which is referenced: you have made the browser follow a hypertext link. That text itself has links to other texts and so on.
The texts are linked together in a way that one can go from one concept to another to find the information one wants. The network of links is called a web. The web need not be hierarchical, and therefore it is not necessary to "climb up a tree" all the way again before you can go down to a different but related subject. The web is also not complete, since it is hard to imagine that all the possible links would be put in by authors. Yet a small number of links is usually sufficient for getting from anywhere to anywhere else in a small number of hops.
The texts are known as nodes. The process of proceeding from node to node is called navigation. Nodes do not need to be on the same machine: links may point across machine boundaries. Having a world wide web implies some solutions must be found for problems such as different access protocols and different node content formats. These issues are addressed by our proposal.
Nodes can in principle also contain non-text information such as diagrams, pictures, sound, animation etc. The term hypermedia is simply the expansion of the hypertext idea to these other media. Where facilities already exist, we saim to allow graphics interchange, but in this project, we concentrate on the universal readership for text, rather than on graphics.
Small-world
The concept of hypertext pages referring to other hypertext pages which on their turn refer to other pages and so on, allows for the creation of a World Wide Web: A global set of hypertext pages interconnected by hyperlinks.
Although this seems to satisfy the original ideas of Dr. Bush to provide: a record of ideas that can be continuously extended and manipulated and a provision whereby any text may be caused to select immediately and automatically another. It is not obvious how this improves the way we can acces that information. Especially the statement made by Berners-Lee that a small number of links is usually sufficient for getting from anywhere to anywhere else in a small number of hops might at first be difficult to belief.
In May 1967, an article The Small World Problem[8] by Stanley Milgram showed promise however. In this article, Milgram disclosed the results of several social experiments to determine the average path length to connect any two people in the United States. Just as webpages, people can be viewed as nodes with direct links to other nodes. These links can be based on family ties, neighbourhood, school, sport, work and so on. These relationships are not predefined, your career/friends/wife/interests came to be without following a set of rules (unless you happen to be royalty) and might even include sports/jobs/hobbies not existing at your date of birth. Generations of people come and go, relationships between people fade and are created. Social networks are continuously changing and yet despite this unpredictable behaviour, Milgram's experiments showed that any two randomly selected people could find each other on average in six hops. A result which later came to be known as six degrees of separation[9].
Mathematical foundation
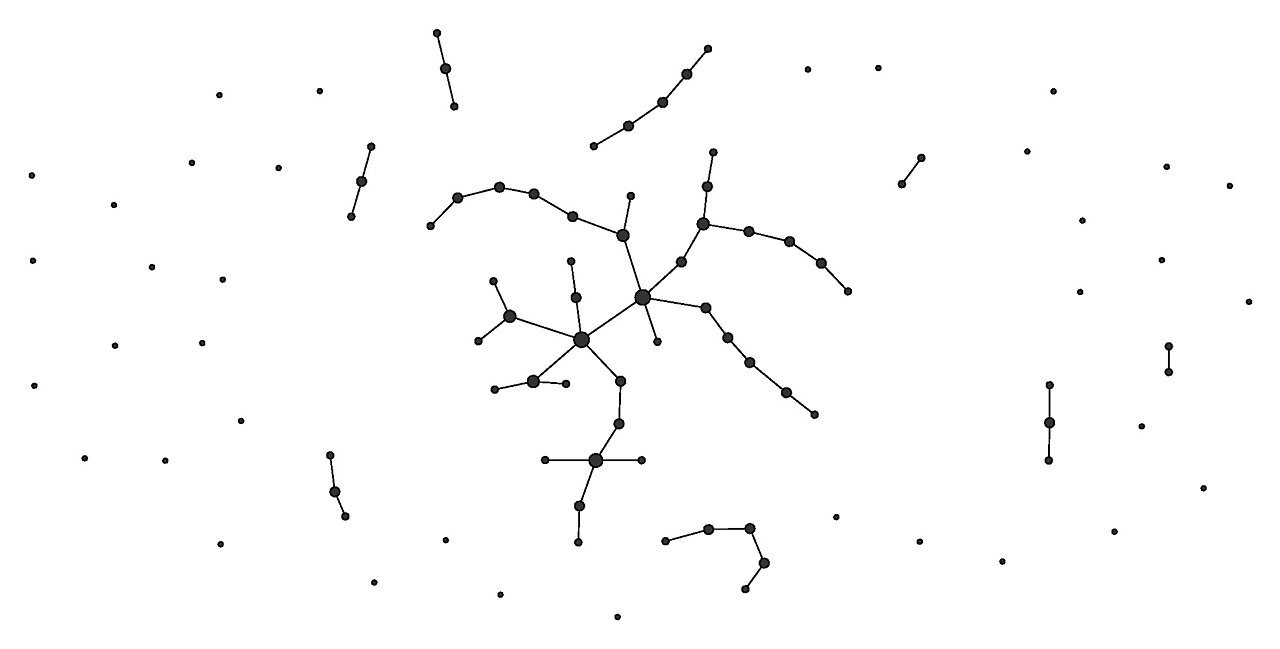
Mathematicians have researched the properties of webs for some time, under the name of graphs[10]. Erdős and Rényi[11] had already devised a model in 1960 to randomly generate a graph. The model starts with a set of isolated nodes and successively adds links between them based on a chosen probability.
Random graph generated by Erdős-Rényi model[11] containing 100 nodes linked with a 1% probability.
They also showed[11] that if this probability exceeds ln (n)/n - where n equals the amount of nodes - the graph will almost surely be a connected graph[12]: A graph in which a path exists between any two random chosen nodes. Dijkstra[13] had already conceived an algorithm in 1956 to find the shortest path length in a connected graph and it can be shown[14] that the average shortest path length of a randomly created connected graph converges to:
Equation for the average shortest path length between two nodes of a randomly created connected graph containing n nodes, with k relations per node.
So assuming there are 7 billion people on the planet (n), with each human being knowing on average 30 other human beings (k), then it requires on average 6.7 handshakes (l) to connect anyone to anyone else.
Small-world network
Although the mathematical prediction seems to correspond with the results of Milgram quite well. The result was still surprising, because a social network of people is not random at all. People are organized in clusters[15] known by mathematicians as cliques[16], groups of nodes in which every node knows (nearly) every other node. Think of your family, your class in school, your football team. You know every member and they know you. That's not random, that's structured. And yet despite this obvious difference, the results of Milgram indicated that our society still exhibits short average path length properties.
Webs (or more generally networks) that contain many clusters and still exhibit low average path length are nowadays known as Small-world networks[17]. The mathematical model used to describe its properties is the Watts-Strogatz model[18].
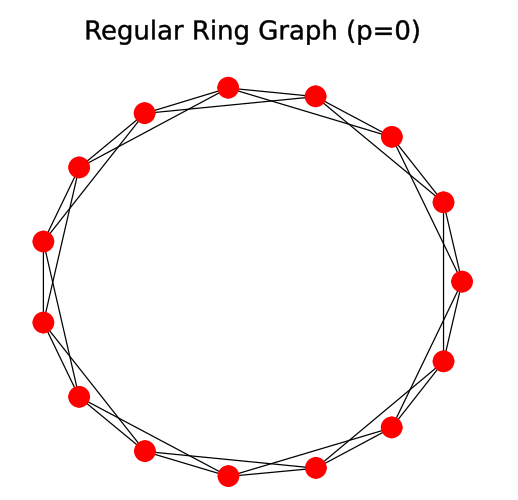
Evolution of Watts-Strogatz model from structured graph to random graph[19].
The model starts as a ring of nodes whose clustering can be set by linking every node to its n nearest neighbours (in our case 4). The ring can be envisioned as a row of houses surrounding a central square. With n set to 4, every house knows its direct neighbours and the neighbours of their direct neighbours. This creates a ring of (overlapping) clusters, each consisting out of 5 nodes.
The model then proceeds with rearranging a certain percentage of the existing links to any random chosen node and thereby moves from a highly structured network to a random one. Perhaps your daughter made a new friend on the central square who happens to live at the other side. This creates a direct link from your home to a cluster at the other side of the ring.
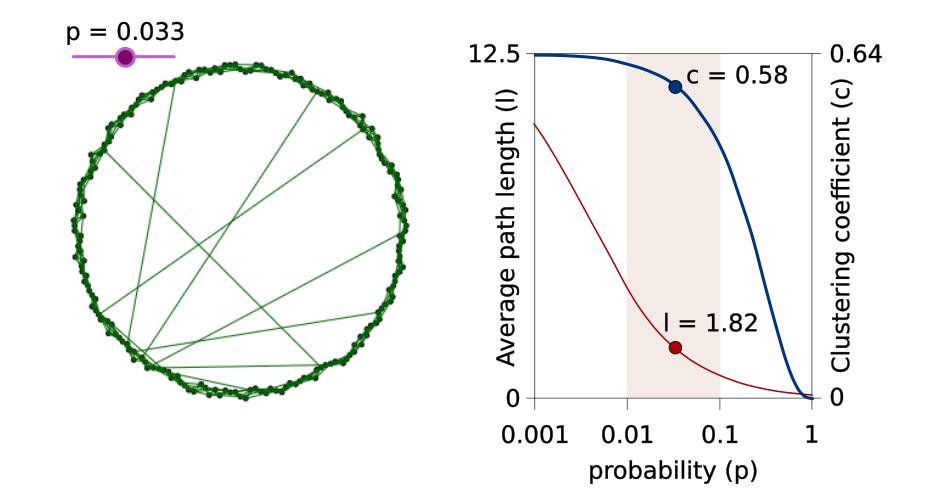
If you plot the clustering coefficient and average path length as a function of the rearringing percentage you get the following.
Average path length (l) and clustering coefficient (c) of a Watss-Strogatz graph as a function of the rearranging percentage (p). The ring on the left shows a network that originally consisted of 200 nodes linked to its 8 nearest neighbours followed by a random rearringing process with its probability set to 3%. The graph on the right shows the corresponding clustering coefficient and average path length. The small-world network zone (high clustering coefficient, low average path length) is coloured in beige[20].
As shown in the beige zone above, only 1-10% of connections need to be rearranged for a highly clustered network to obtain small-world properties. Perhaps you have an uncle that emigrated to Canada or a friend that went to a different high school, these are both links that provide direct access to different clusters.
Hubs
Finding information in just a small number of hops is what makes the hypertext world so exciting. The previous sections showed how this is possible in such highly dynamic and uncontrolled environments as the World Wide Web or social networks, where one is free to create any kind of cluster and nodes are continuously created, modified and cancelled. Small-world properties can be obtained by adding a small amount of direct links between nodes belonging to different clusters.
Remarkable as that may be. The World Wide Web does not solely rely on random chance for a node to be found (although it would work). It developed another network property which we nowadays know as hubs[21]: Nodes with significantly more links than other nodes. Real world hub examples include central railway stations or main airports. In the case of social networks, think of your local dentist, physician, grossery store owner, who are bound to know almost everyone in a small community. On the World Wide Web, these hubs are generally aggregators[22]: Websites that make summaries of web content based on a certain theme or function. A few famous examples are shown below:
I want to buy (https://www.bol.com/).
The webstore of the Netherlands, offering online purchasing through various subcontractors.
I want to rent (https://www.voordeeluitjes.nl/).
The holiday website of the Netherlands, offering holiday houses/appartments/hotels through various subcontractors.
I want an update (https://www.nu.nl/).
The news website of the Netherlands with worldwide coverage.
I want to know (https://en.wikipedia.org/).
Global hub for information on almost any topic with references to external articles for further reading.
I want to find (https://www.google.nl/).
The hub that allows you to find all other hubs. Google deserves to be called the central hub of the World Wide Web.
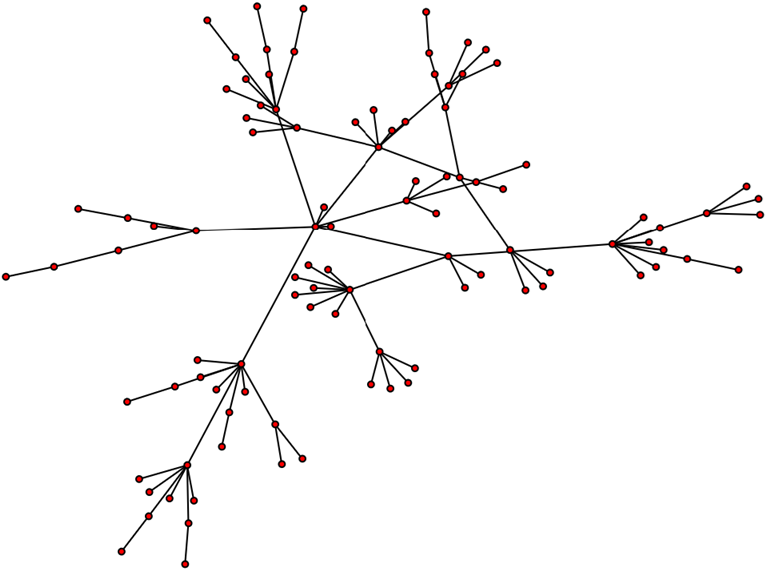
The mathematical model used to create random networks with hubs is called the Barabási–Albert model[23].
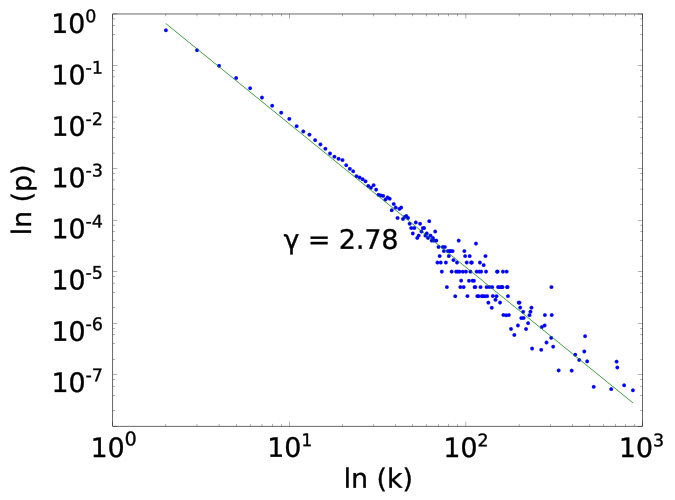
Left: Random graph generated by the Barabási–Albert model[24]. Middle: Probability of finding a node with k links[25]. Right: Fit through modeled data[23].
The model starts as a connected graph with m0 nodes. When a node is added, it is given m≤m0 links to already existing nodes in the network (so at maximum, the new node is connected to every existing node). Common values for m are low, the graph in the figure above was generated with m=1 for example. Just as with the Watson-Strogatz model, this implies that the average number of links per node is predefined. When m=1, every new node has exactly one link. In contrast to the Watson-Strogatz model, the node that is linked to is not chosen at random but with a probability proportional to the links the existing node already has.
Where pi is the chance of being connected to a node i, which is equal to the number of links the node i already has (ki) divided by the total number of links in the network, such that ∑i pi equals 1.
The method is known as preferential attachment[23]. The reasoning behind such a mechanism is twofold: Firstly, nodes with many links are by definition well known and hence have a higher change of being connected to by someone new. Secondly, it assumes that new nodes want to be found and by connecting themselves to one of the well known hubs, they increase the change that they are found themselves. In short, everyone wants to be found on Google. The method causes a positive feedback cycle: The more links a hub aggregates, the more well known it becomes, the higher the change that new nodes will attach themselves to it.
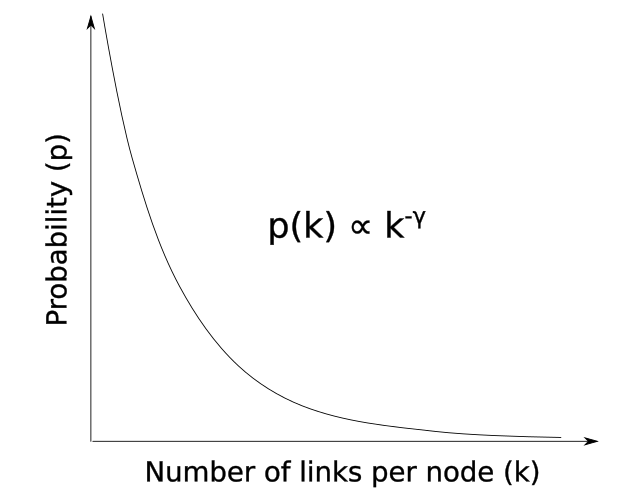
The Barabási–Albert model results into a graph in which the probability of finding a node with k links follows a so-called power law[26] as depicted in the middle figure above. The value of gamma can be found[23] to be close to 3, which implies that chances of finding a node with 10 times more links than the current one is 103 less. As this behaviour is true for any node one might have selected, the resulting graphs are also often referred to as scale-free networks[25]: Networks whose links per node distribution looks equal regardless of zoom level.
The bottom line is that hubs are scarce and well connected, allowing them to act as the main airports of the World Wide Web. The average shortest path length of the Barabási–Albert model can be shown[24] to equal:
Where l is the average shortest path between nodes and n is the number of nodes.
Note that in contrast to the Erdős-Rényi model, the average shortest path is independent of the (average) number of links per node. This is because most nodes are closely connected to a hub and the hubs quickly direct you to your final destination. As a result, all other non-hub links the node might have are of little consequence to the shortest path.
Does this mean that we should abandon the idea of clusters or direct links between nodes? No, hubs should be viewed as a structured way to reach the vicinity of your destination, clusters and direct links take care of the local navigation. This is similar to the original experiment of Milgram where letters reached the intended vicinity (New York for example) quite quickly, but local networks were required to find the adressee within New York. In short, hubs bring you to local webs, local webs bring you to local nodes.
Guidelines
So what does this all mean if you want to create a webpage yourself?
Feel free to organize your webpages as you want. There are no rules.
Make direct links between your pages with related topics. This creates your cluster.
Make one or more overviews that allow structured access to your webpages. These become your hubs.
Create direct links between your own pages and those of external clusters. This connects your content to the World Wide Web.
Upload your pages to a webserver[27]. This ensures that other people can link to your content as well.
The picture below shows two examples of web pages: One from Wikipedia and one from this series.
A few examples of how hypertext can be organized.
The red sections provide access to hubs. In the case of Wikipedia, access to the main hub is always found at the top of the page together with a search bar. The hub to the local cluster (in this case network science) is hovering besides the main content. The page from this series looks quite similar. It too provides access to the hubs at the top of the page (as well as the bottom). In our case, there are three: The ones on the outer left/right are main hubs and make sure that all pages of the series can be found in a maximum of 2 hops (one to the hub, one to the page). The hub called "Project Eternal" is a structured list by topic, the hub called "Glossary" is a flat list of introduced terms/definitions, both can be searched by a simple "CTRL-F". The third hub positioned in the middle allows access to related topics in the local cluster and is the equivalent of the "hovering section" of the Wikipedia page.
For both examples, the green boxes contain the main content of the page with direct links to related topics within the cluster. The blue sections contains direct links to related topics on the World Wide Web. For this series, these references state both a brief description of the connected node as well as the external cluster it belongs to.
This concludes our section about hypertext. To experience just how powerful the concept is, I recommend visiting Six degrees of Wikipedia[28]. A website that shows you the shortest route between two seemingly unrelated Wikipedia pages. For instance, it took no more than 3 hops to link "Twin Towers" to "Monkeys in space".